Computer Systems: Linking
《深入理解计算机系统》中Linking这一章对编译过程中链接器的作用做了非常详尽的介绍,对于程序员而言可能在算法、数据结构以及编程语言上花的时间比较多,然而对于计算机如何将代码编译为可执行文件的过程缺乏系统的了解,然而如果需要了解Linux下程序完整的编译执行过程,阅读本书的相关章节是十分必要的,笔记比较长所以分成两部分
基本概念
Linking的定义:将各种代码和数据部分收集起来并组合成一个单一文件的过程,要理解这句话的含义首先需要明白GNU系统的一般编译流程:
当然链接这一步并不一定要在程序编译时进行,Linking操作的对象是已经编译完成的目标文件,输出的结果就是可执行文件,链接器在整个编译过程中起到以下两个作用:
1.解析.o文件将符号引用与定义联系起来
2.为指令与变量分配运行时地址可重定位目标文件
要了解链接器的工作原理首先需要清楚它的输入文件,.o文件
在弄清可重定位目标文件的内容之前,一些平时不好的习惯可能会引发概念上的混淆 比如在Linux上编译程序时,我们可能会执行这样的指令:
gcc -o *main.o* -I(dirs for header files) -l(paths for libraries)之后可以直接在控制台执行./main.o,这样看来我们似乎直接执行了可重定位目标文件,然而这条指令中的.o文件是编译程序输出的最后结果,也就是说我们把可执行文件的名字命名成了main.o,而实际上汇编器生成的.o文件位于tmp目录下,因此在实际写程序时最好把文件的名字区分开,以免混淆。
文件格式
书中可重定位目标文件的文件内容非常繁杂,简单而言该文件分为许多的section,每个section都包含了,总结下来分为以下三类
1.存储机器指令与全局变量(如.text, .data, .bss)
2.存储指令与变量的位置相关信息(即重定位信息, 如.rel.text, rel.data)
3.存储函数与变量的各种属性(.symtab)需要注意的是链接器仅仅考虑全局变量,函数中的局部变量由栈管理
符号表.symtab
符号
从程序员的角度看符号是一个个的变量名和函数名,而对于链接器而言只是一些字符串而已,因此在这里被称作符号,符号表包含了原文件中各个符号(函数和变量)的信息,有一种符号不在链接器的管理范围之内,符号表不包含对应于本地非静态程序变量的符号,因为这些符号也由栈管理
需要注意的是当变量名前面指定了static关键字之后,无论该变量定义在函数内部还是外部,都会存储在.o文件的符号表中,对于函数也同样如此。
符号表的格式
如果从数据库的角度看,符号表可以看作是一张普通的关系表,每个符号及其相关属性都可以被看作是一个元祖,整张表中包含的属性包括:
符号的偏移量(存储格式为int型,可以理解为下标)
符号的地址
符号的类型(数据或者是函数)
符号的大小
书中给出的例子非常清楚,以main.o为例,基本的格式如下图: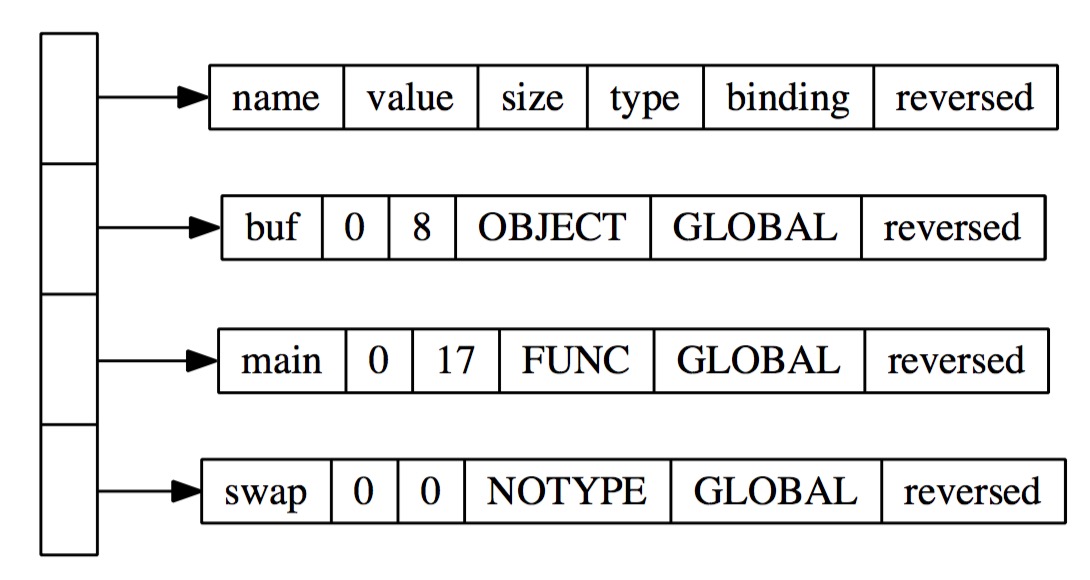
附上源码:
/* main.c */
void swap();
int buf[2] = {1,2}
int main(){
swap();
return 0;
}符号解析
全局变量解析
之前提到链接器的作用之一就是解析.o文件,其实主要解析的就是符号表中的符号,实际上链接器在这一步所做的工作是将原文件出现的变量的引用和符号表中的符号定义联系起来
如果符号的定义就在原文件中,那么链接器可以直接联系引用和定义,但是如果符号不是定义在原文件中,链接器假设该符号定义在其他某个模块中,同时如果出现多个文件同时定义相同变量的情况,比如一个文件中声明全局变量,另一个文件定义全局变量
- 强符号:已初始化的函数及变量
- 弱符号:未初始化的函数及变量
当出现多个同名的全局变量时,链接器遵循以下三个标准进行解析: * 不允许有多个强符号 * 如果有一个强符号和多个弱符号,那么选择强符号 * 如果有多个弱符号,那么从这些弱符号中任意选择一个
简单而言链接器不允许多重定义,并且会优先连接变量定义的位置
通过对符号解析部分的介绍我们也明白了为什么写程序时不鼓励定义太多的全局变量的原因,当程序架构比较大,每个人分别编写自己的模块时,很容易发生全局变量的定义冲突,而且编译器不会报这样的错误,因为已经涉及到代码整合时的程序逻辑层面的错误而不是编程语言规范的错误。
与静态库连接
在阅读此章节之前我认为静态库在编译时进行链接,而动态链接库在运行时进行链接,这种理解其实并不正确,这两种库的不同之处不在链接的时机而在于它们构成和设计思想
静态库
由于标准函数会被广泛使用,如果在编译时直接生成这些函数的代码不仅增加编译器的工作量,同时当这些函数更新时也难以维护编译器,如果为每个函数都生成一个.o文件,那么我们需要写很冗长的链接命令,同时也会消耗多余的存储空间,费时也费力。
静态库可以很好地解决链接这些“常用函数”的问题,一个静态库以一种称为存档的特殊文件格式存放在磁盘中,可以理解为是一组.o文件的集合。
直观上讲,当我们需要链接某个函数时,我们只需要链接该静态库中的对应模块,即该函数对应的.o文件就可以了,因此静态库只需要向链接器提供每个模块的大小和位置就可以了。
对于自己原先的对于静态库的理解,当编译时添加-static参数后,链接器会生成一个完全链接的可执行目标文件,也就是在编译时进行链接,这样生成的可执行文件可以直接在内存中执行,因此链接的时机和链接的库的类型其实并无多大关系
使用静态库解析引用
回到符号解析,之前介绍了解析符号时,符号定义在原文件中的情况,那么如果符号定义在静态库中怎么进行链接呢?
首先链接器会按顺序扫描.o文件和静态链接库,在扫描过程中链接器会维护一个.o文件的集合E, 一个未解析的符号集合U,以及一个在输入文件中已定义的符号集合D,链接时按照以下流程进行链接:
按照笔者理解U和D可以认为是两个数组,U用来存储未匹配到定义的符号,而D存储已定义的符号,而E用来存储所有输入文件中链接器对符号的解析结果
需要注意的链接器只会链接在U中的符号,由于链接器是按顺序扫描的,因此如果符号的定义出现在引用之前并且引用后再也没有出现该符号的定义,那么就会出现扫描结束后U不为空的情况,导致链接出错
重定位
完成符号解析之后,代码节与数据节的大小就已经确定,之前提到链接器的第二个作用就是分配运行时地址,重定位的目的是为了让CPU知道符号在存储器中的位置,因此重定位分为两步:
1.将所有输入模块的同类型节(如data节)合并,并将运行时的地址赋给这些合并后的“聚合节”,同时赋给输入模块的每个节
2.修改代码节和数据节中对每个符号的引用,使得他们指向正确的地址这样写可能还是不够清晰,简单而言第一步为每个节分配运行时地址,而第二步为节中每个指令或数据分配运行时地址,而为了给指令与数据分配地址,我们需要明白重定位条目的概念
`重定位条目`
在介绍可重定向目标文件的内容时提到过有section负责存储重定位信息,如代码的重定位信息在.rel.text中,数据的重定位信息在.rel.data中,这两个张表告诉链接器需要修改的引用在节中的什么位置以及重定位的类型(如何修改引用的地址),表中每一项就是一个重定位条目,当链接器找到节中的符号后根据重定位类型计算该符号运行时地址。书中介绍了两种重定位的类型:PC相对引用与绝对引用
PC相对引用
相对引用使用基地址加偏移量的方式寻址,基地址存储在程序计数器PC中,所以我们只需要计算出偏移量,CPU就可以找到该指令或者数据的运行时地址了,假设我们已经知道了节的存储器地址和符号的运行时地址,计算方式如下:
计算swap在节中的地址 refptr = s+r.offset
计算引用swap的指令地址: refaddr = ADDR(s) + r.offset
计算偏移量 *refptr = ADDR(r.symbol) + *refptr - refaddr书中给的例子比较难懂,首先抛开那个 *refptr不看, 参考书3.6节的内容,在进行PC相对寻址时,目标跳转地址就是例子中swap函数的地址,而链接器需要修改的就是引用swap的指令的目标编码,这两者之间的关系为:
目标编码 = 目标跳转地址 - PC因此在求目标编码时,实际的目标跳转地址等于swap的地址:0x80483c8,从3.6节的例子中我们可以看出PC的值是在当前指令的地址基础上+4,即当前指令的后面一条指令,因此实际上原式等于
目标编码 = 目标跳转地址 - (当前指令地址+4)当前指令自然是引用swap的指令地址,该地址可以用节基地址加偏移的方式求得:
引用swap的指令地址 = 节基地址 + 引用偏移 绝对引用
绝对引用理解起来就容易许多,修改引用时直接把值修改为目标跳转地址和初始值的和,CPU会直接通过该引用内的值查找对应的数据
按照书中的例子,bufp0需要重定位指向数组buf的首地址,又由于原本.data节中的重定位条目中的初始值为0,所以直接把buf数组的首地址赋给bufp0即可。由于重定位的对象是指针,因此该过程类似于为指针赋值的过程。