这篇日志主要用来整合近几年在ImageNet竞赛中获得较高成绩的CNN网络相关论文的笔记,因为思想都是基于CNN,在实际训练网络或者网络结构上有创新的地方,因此就统一写成一篇文档了,实验结果部分就省略了,主要集中在文章亮点的地方,一共有4篇相关的论文(Alexnet, GoogleNet, VGGnet和OverFeat),会保持长期更新。
caffe的example中给出了Alexnet和GoogleNet的模型,熟悉caffe的话可以直接看对应的depoly.prototxt,比较直观
AlexNet
Architecture
Alexnet是ILSVRC2012的冠军,网络结构比较深但是很有规律,关于这篇论文有许多在实际train网络时候的一些比较有用的trick,AlexNet的训练过程如下:
- rescale the image such that the shorter side is of length 256, and crop the centeral 256*256 patch from the resulting image 先rescale后crop的方式处理图像scale的问题
- 5个卷积层3个pooling 层,且神经元的激活函数使用的是ReLu,降低计算量
- Training on multiple GPUs,现在看来GPU并不是非常好,但是多GPU并行计算
LRN(Local Response Normalization) Normalization 笔者认为这是本文的亮点,虽然ReLu不需要输入normalization但是引入LRN可以提升1.4%至1.2%的准确率,简单来说就是对ReLu层的输出进行归一化,归一化公式如下: \[b_{x,y}^{i} = a_{x,y}^{i}/(k+\alpha\sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^j)^2)\] 其中i和j表示第i/j个卷积的kernel,而a表示ReLu的输出,b表示归一化后的结果
注:caffe的LRN层实现中提供两种Normalization的方式:通道内归一化和通道间归一化,这个在caffe源码笔记中会详细讲解Overlapping Pooling 传统的pooling方式将feature map分成独立的grid每个grid进行pooling,而本文中采用滑动窗口的方式,每次滑动的stride小于窗口的大小,实验证明,这样的方法能提升0.4%-0.3%的准确率
整体网络结构直接上图: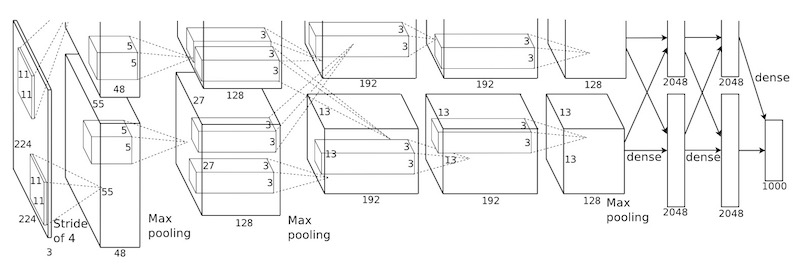
Training Details
Data Augmentation
笔者认为这一部分内容在工业界相当有用,Deep learning需要大量的数据,而当数据集不够充足的时候如何做好数据增量十分关键,同时还能减少overfitting
文中介绍了两种方法:
- generating image translations and horizontal reflections(截取部分图像和镜像翻转)
- alter the intensities of the RGB channels(借助PCA改变RGB通道的像素值)
Dropout
Dropout有专门的文献介绍,简单来说就是每次Forward的时候神经元以某概率输出0,这样在BP的时候该神经元的权重也不会更改
GoogleNet
GoogleNet以及其复杂的网络结构而闻名,ILSVRC2014的冠军,一共22层的网络看上去复杂但依旧有规律可循,文章中主要的亮点在于Inception结构
Motivation
单纯加深网络会导致过拟合问题出现,且由于90%的计算量集中在最后的全连接层,为了降低计算量,文中提出了将全连接层替换为稀疏连接层。
Architecture
Inception Module是构成整个GoogleNet的关键组件,其主要思想就是用密集的组件来逼近稀疏的卷积网络结构
Naive Inception结构如下图,假设每个Inception视作一个部件component,Inception在接收上一层的结果后,用不同尺寸的卷积层(1*1,3*3,5*5)和pooling层并行计算结果,将每层的结果合并起来,最后经过一个滤波器进行分组
但是会带来一个问题:即使是一个合适数量的卷积,也会因为大量的滤波而变得特别expensive。经过pooling层输出的合并,最终可能会导致数量级增大不可避免。处理效率不高导致计算崩溃。
因此改进方案是:在需要大量计算的地方进行降维。压缩信息以聚合。1*1卷积不仅用来降维,还用来引入非线性特性。
GoogleNet

GoogleNet
比较有趣的地方是网络中有三个softmax分类器,文中作者提到对于浅层网络而言,中间网络产生的特征非常有辨识力,在这些层中增加一些额外的分类器能增加BP的梯度同时提供额外的正则化,每3个Inception module会增加一个Softmax分类器。在训练过程中,损失会根据权重叠加,而在测试时丢弃。
Training的时候使用了AlexNet中的trick
Insights
- approximating the expected optimal sparse structure by readily available dense building blocks is a viable method for improving neural net- works for computer vision.(虽然增加了计算量但是能显著提高分类的准确率)
- For both classification and detection, it is expected that similar quality of result can be achieved by much more ex- pensive non-Inception-type networks of similar depth and width.(没有使用bounding box regression,说明Inception同样适用于detection和localization的task)
VGG net
VGG Net是ILSCVRC2014 classification的第二名,localization的第一名,网络结构上比其他网络都要来得复杂(实验过程中卷积层最多有16个),但是文章中对如何构造复杂网络和训练网络的描述非常详尽,相信对research会有很多帮助
Network Configuration
Training
网络的training借鉴了AlexNet在训练中使用的方法,同样是momentum SGD+dropout,处理图像尺寸的方法相同,做数据增量的方法也相同,但是由于一共有5个网络需要训练,且网络深度依次递增,因此在参数初始化时作者提出:
最简单的网络使用随机初始化,而后面的网络中最前面的4个卷积层与最后3个全连接层参数用先前网络的参数初始化,其他层使用随机初始化,这种首先训练简单网络,随后使用其参数来初始化复杂网络的训练方法是一种非常合理且高效的方式
值得一提的是文中对比了7*7的卷积层与三个3*3的卷积层之间的对比,相比较而言多个小的卷积层级联能在引入更多的linear rectify之外同时还能降低卷积层参数的数量。
整个训练过程如下:
- Classification
- 设计结构复杂度依次递增的网络
- 在Image size的处理上,作者提出single-scale和multi-scale的方法, single-scale的方法与AlexNet相同,先resize后crop,multi-scale的方法类似于随机采样,每次rescale之前在一个固定区间内(如[256,512])选取一个scale,这样每个图像的尺寸就不同了,但是怎么处理feature长度不同的问题作者似乎没有说明
- 每次训练新的网络之前用之前网络的参数进行初始化以加快收敛速度
- Localization
- Training Localization的方法与classification相同,只不过用的是Euclidean Loss
Testing
在testing阶段,网络接收图像数据之前首先需要把图像rescale到固定大小,作者称之为test scale,之后首先通过fc层计算,我们把fc层看作一个卷积窗口为1*1的卷积层,得到的feature map维度与object类别相同。
这样做的好处是对比首先crop再通过卷积计算feature map的做法,直接通过fc层计算可以减少许多重复的卷积计算量,crop出来的图像之间必然会有重叠的部分,这些重叠部分增加了测试时卷积的计算量,但是笔者认为既然在训练时使用crop来做数据增量,测试时用crop可以增加网络输出的置信度(每个crop输出分类结果,这个结果甚至可以用来做类似bagging的训练),如果面对实时性要求比较高的情况,对整张图片应用fc层是比较可行的方法。
OverFeat
OverFeat最出彩的地方在于使用一个CNN解决Classfication、Localization和Detection的任务,以及Sliding Window和CNN的结合,每个任务使用的神经网络不同之处只在最后的分类器,大牛Yann LeCun的文章
网络结构的前五层与Alexnet相同,Alexnet的网络结构已经成为feature extraction的经典结构了,如下图所示: 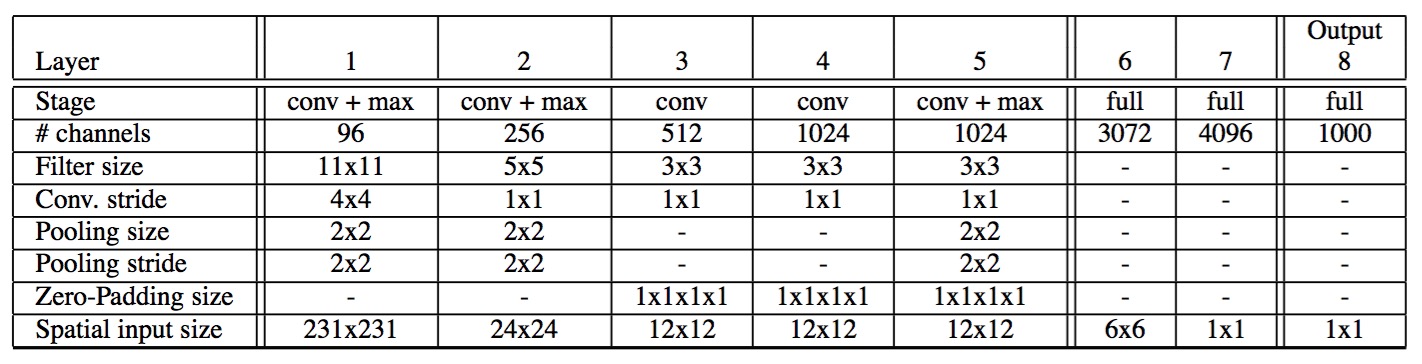
Multiscale training
训练时大多数人都会碰到Multiscale的问题,本文中作者提出在pooling时引入偏移量的方法,具体过程如下图 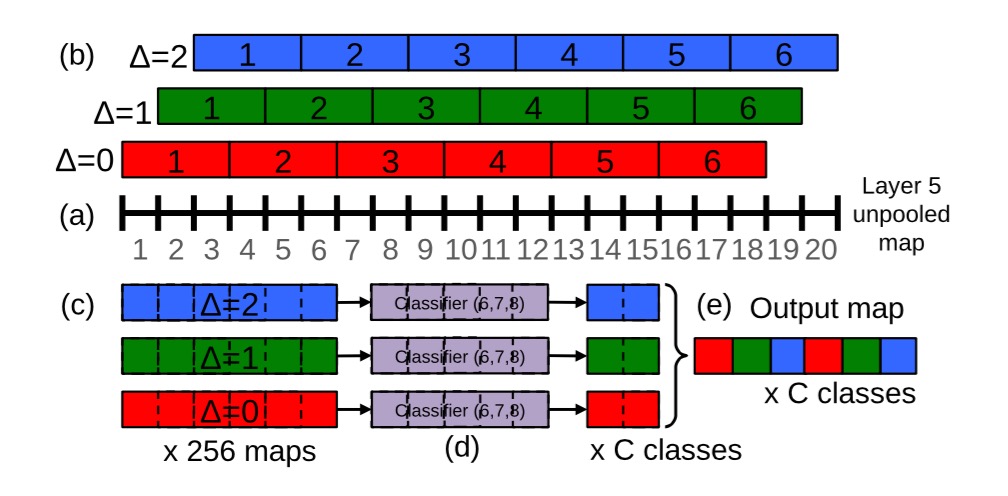 按照笔者理解,原始的3*3pooling的起始位置为(0,1,2),其实就是使用stride步长为1的pooling层,之后按照原始stride进行分组,得到多个分组的pooling向量之后使用滑动窗口的方式得到feature map,重新将原先分组的结果合并成一个向量作为整张图片的feature map,无论图像的尺寸多大,使用stride为1的pooling层能最大程度上保持原始信息,并且分组之后每一个feature map向量长度保持一致。
按照笔者理解,原始的3*3pooling的起始位置为(0,1,2),其实就是使用stride步长为1的pooling层,之后按照原始stride进行分组,得到多个分组的pooling向量之后使用滑动窗口的方式得到feature map,重新将原先分组的结果合并成一个向量作为整张图片的feature map,无论图像的尺寸多大,使用stride为1的pooling层能最大程度上保持原始信息,并且分组之后每一个feature map向量长度保持一致。
Sliding Window
训练CNN时要求输入图像的大小固定,但是如果输入的图像尺寸比原先大怎么办呢?对于一个训练好的CNN来说,卷积核的大小和数量以及每一层feature map的个数是固定的,但是feature map的大小是可以改变的。
当测试样本和训练样本大小相同时,CNN最后一层的每一个节点分别输出一个0~1的实数,代表测试样本属于某一类的概率;当测试样本比训练样本大时,CNN最后一层每一个节点的输出为一个矩阵,矩阵中的每一个元素表示对应的图像块属于某一类的概率,其结果相当于通过滑动窗口从图像中进行采样,然后分别对采样到的图像块进行操作 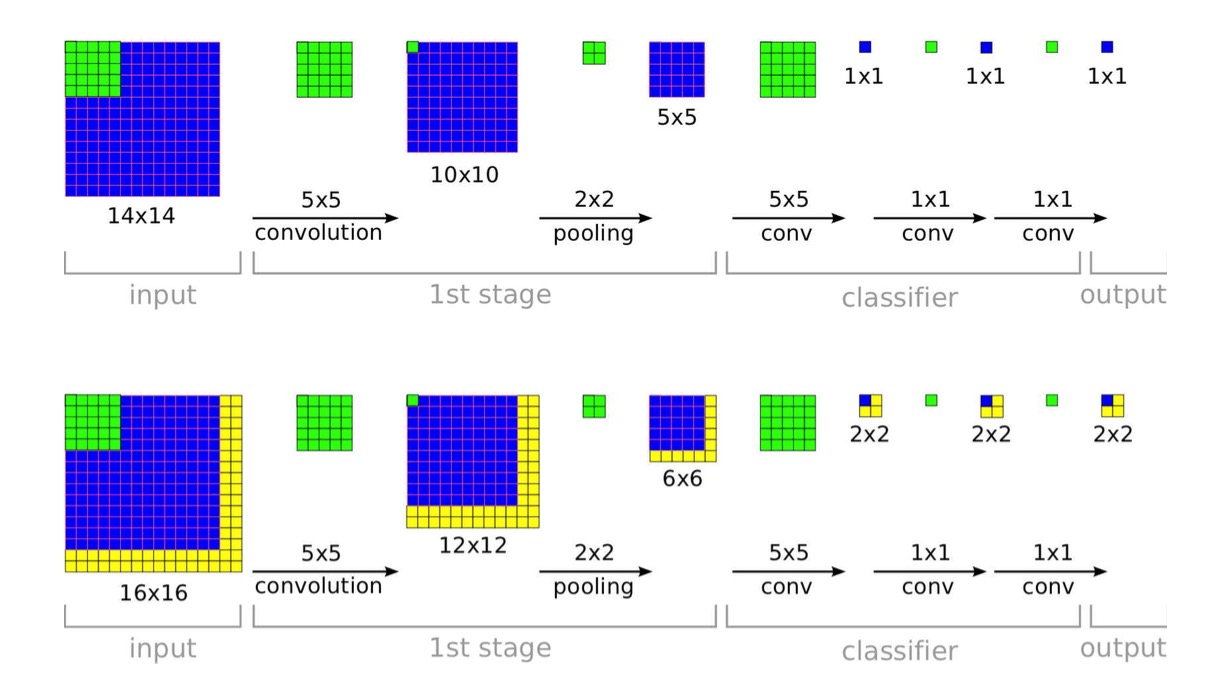
Localization
将原先classification网络的最后一层softmax替换为Bounding box回归: 最后一个pooling层输出的feature map通过两个全连接层映射到一个输出层,输出被看作一个由4维向量构成的矩阵,每个向量对应了原始图像某一块区域中的object的bounding box的位置,之后开始合并各个区域中的bounding box直到两个bounding box之间的match score足够大。
值得注意的是这个regression网络对于每一个object类别都会输出一个bounding box,前面一节中提到的classification的网络会输出图像分类的概率值,于是每一类的bounding box都会对应一个置信度,在合并之后网络会输出一个置信度,这个置信度就是原先所有class置信度的最大值,因此完成合并之后网络的输出是一个带有最大confidence的bounding box
Detection
物体检测的方法其实就是结合了classification以及localization,但是文中没有给出具体的训练细节,笔者认为与Localization非常相似,因为直观上只要根据置信度删选Localization输出的bounding box,之后取每一个图像块中置信度最大bounding box就可以了,可以看出相对于RCNN的做法,OverFeat比较暴力一些,对每块图像区域都会输出1000类的预测结果,其计算量想必也不小