Fast RCNN在RCNN的基础上修改了网络结构,同时加快了训练速度并且降低了训练成本,从工程角度说RCNN提出了思路而Fast RCNN的实用性更强
Motivation (Drawbacks of RCNN)
- RCNN的训练方式按照一个一个阶段分的比较开
- 训练时RCNN会将每个proposal的特征向量存储在硬盘上,不仅占用存储空间,时间上也因为读写磁盘而变得很慢
- 在进行detection测试时耗时长
Fast RCNN Training
文章的亮点在于对原来网络结构的改进
- RoI Pooling Layer 按照作者所述,该层的思想类似于SPPnet,我们假设最后一个卷积层得到N个feature map(这些feature map包含原始图像的所有信息),而我们只想提取感兴趣的部分,因此这就需要引入RoI了
将这N个feature map和selective search得到的R个region proposal输入到RoI pooling层中,根据RoI中指定的区域对原始的feature map进行pooling得到这R个region proposal的N个feature map
由于各个RoI的大小不一样,而为了使得每个RoI pooling出来的feature长度相同,采用不同大小的pooling窗口而已
对原始CNN网络结构的修改 修改主要有3处
- 将最后一个max pooling层替换为RoI pooling层
- 将最后一个全连接层和softmax层替换为两个同并列的层
- K+1个class的分类器
- Bounding box回归(Localization)
- 修改网络的输入,使其接收N个image和R个RoI 最后网络结构如图所示:
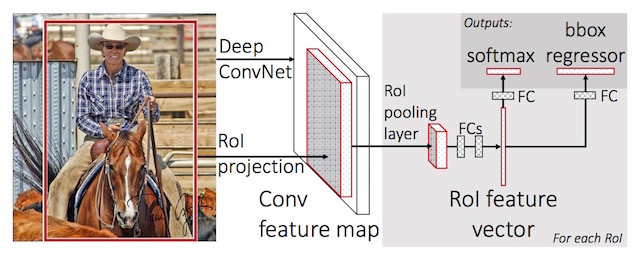
核心在于使用RoI pooling层直接提取原始feature map中属于RoI的那一部分
Fine-tuning微调
网络结构变化带来的是训练方式的变化,作者在现有的CNN分类网络上进行了微调,类似于RCNN中的domain-specific fine-tuning,只不过这次是针对网络结构而调整训练方式
- Multi-task Loss
简单来说就是将分类的Loss和bounding box回归的Loss做了加权和
\[ L(p,k^*,t,t^*) = L_{cls}(p,k^*) + \lambda[k^*\ >\ 1]L_{loc}(t,t^*) \]
\[ smooth_{L_1}(x) = \begin{cases}0.5x^2 \ &if \ |x| < 1 \cr |x|-0.5 \ &otherwise \end{cases} \]
第一部分是softmax分类器的Loss,第二部分是regression的Loss,值得注意的是第二部分有个指示函数,说明不会计算那些background类型的proposal的locaolization误差
- mini-batch sampling
每一次SGD的batch使用2个image和128个RoI,每个batch中RoI的构成: 1.25% ground truth中的bounding box IoU>0.5, 2.75% IoU < 0.5, 看作background example
- BP through RoI pooling layer
在进行反向传播时RoI pooling layer有些许不同, 参与pooling的不再是整幅图像而是可能有重叠的RoI区域,计算公式如下:
\[ {\partial L \over \partial x} = \sum_{r\in R} \sum_{y\in r} [y\ pooled\ x] {\partial L \over \partial y} \]
y代表pooling后的值, 反向传播的思想是要将每个y的偏导传递给所有参与pooling的变量x,这也就是指示函数 [y pooled x] 的含义,在这里x代表的是原来RoI中的元素
- Scale invariance 如何处理输入图像尺寸不一的问题? 作者给出了两种方案:
- brute force 强制把图像resize到同一尺寸下
image pyramids 利用图像金字塔,把图片resize成不同的大小,选取其中最接近optimal scale(也就是227*227)的大小用作训练。
Fast RCNN Detection
- Truncated SVD 全连接层的计算时间太长,占用了整个前向传播的一半时间,因此在进行矩阵乘法时,作者采用SVD将权重矩阵\(W (u \times v)\)分解为三个矩阵的乘积:
\[ W \approx U \Sigma_tV^T \]
SVD分解后的U和V都是对称矩阵 最后一个全连接层被分解为两个子层:第一层的权重矩阵为$ _tV^T \(,第二层的权重矩阵为\)U\(,因此整个参数的个数由\)uv\(变成了\)t(u+v)$,当t比较小(意味着原参数矩阵的特征值少)的时候计算时间就会大大减少 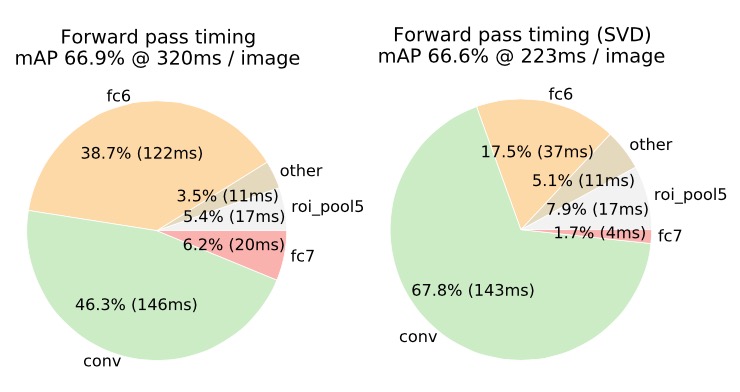
Experiment Insights
卷积层和全连接层一样需要fine-tuning,且浅层的卷积层没有微调的必要。 > decrease mAP from 66.9% to 61.4%
首先用classification loss训练,之后加入bbox regression训练效果更好 > improvement ranges from +0.8 to +1.1 mAP points
- trade-off: speed > performance improvement brought by multi-scale
- More data brings higher mAP
- Softmax slightly outperforms SVM
Sparse proposals(selective search) improve detection quality and dense proposals(sliding window) free the heavy running cost.